Cómo aislar la voz de una canción

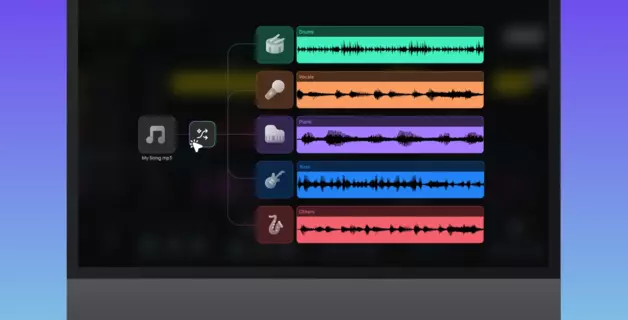
Para aislar la voz de una canción (o eliminarla por completo y obtener una pista instrumental limpia), se utiliza un eliminador de voz basado en IA: una herramienta que analiza la mezcla completa y la divide en pistas de instrumentos individuales, también llamadas «stems». Sube tu archivo, selecciona una división en 2 stems y obtendrás dos resultados: uno con solo la voz y otro con el resto (el instrumental).
En Amped Studio, esto ocurre dentro de tu sesión. Su herramienta AI Splitter integrada te permite aislar las voces en línea sin necesidad de instalar nada: los stems aparecen directamente en tu proyecto como pistas.
Sigue leyendo para saber más sobre esta técnica, así como:
- Los usos más comunes de una voz aislada
- Cómo extraer las voces de una canción utilizando el AI Splitter de Amped Studio
- Cómo funciona realmente el aislamiento vocal con IA
- En qué punto se encuentra actualmente la tecnología, y qué puedes esperar del resultado
- Una breve nota sobre los derechos de autor
Usos habituales de las voces aisladas
Eliminar la voz y conservar la pista instrumental
El uso más directo de cualquier extractor de voz: eliminar al cantante y conservar la música. Lo que queda es un instrumental limpio: el arreglo completo sin la voz principal por encima.
Así es como se crean las pistas de karaoke personales cuando no existe una versión oficial. También es la forma en que los músicos extraen una pista de acompañamiento de una grabación terminada para ensayar sobre ella, grabar una versión o utilizarla como referencia compositiva. Si alguna vez has querido una versión karaoke de una canción que no la tiene, esta es la respuesta.
Extrae una versión a capela de una canción para remezclas, mashups o sampling
La dirección opuesta: mantén la voz, descarta la música. Un a capella es la pista vocal aislada por sí sola. Una vez que la tengas, puedes superponerla sobre un ritmo diferente, transponerla a una nueva tonalidad, mezclarla en un mashup, o ir más allá y cortar fragmentos de ella —una frase aquí, una respiración allá— y utilizar esos fragmentos como materia prima en una producción completamente nueva. Tanto si utilizas la voz completa como por partes, el proceso del extractor de acapella es el mismo: separa la voz de la canción y luego llévala donde el proyecto lo requiera.
Esta es una práctica habitual para los DJ que crean sets en directo, los productores que remezclan sin tener acceso a los archivos de sesión originales y los creadores de ritmos que samplean a partir de grabaciones existentes.
Amped Studio como extractor de voces: paso a paso
El AI Splitter de Amped Studio se ejecuta íntegramente en tu navegador: sin descargas ni instalaciones. Las pistas aparecen directamente en tu proyecto como pistas, lo que significa que todo lo que ocurra a continuación —edición, efectos, arreglos, añadir nuevos elementos— permanece en el mismo entorno sin cambiar de ventana ni volver a importar archivos.
Paso 1: Abre Amped Studio
Inicia sesión o regístrate en ampedstudio.com. La sesión se abre en tu navegador en cuestión de segundos.
Paso 2: Haz clic en «Dividir cualquier canción»
La pantalla de bienvenida te da acceso directo al AI Splitter. Haz clic en ella para abrir el separador de pistas.

Paso 3: Sube tu pista y elige tus pistas
Arrastra tu archivo de audio o selecciónalo de tu biblioteca. Para el aislamiento vocal, la opción de 2 pistas te ofrece una pista vocal y una instrumental. Si quieres un desglose más completo —con la batería, el bajo y el piano también separados—, elige 4 o 5 pistas.
La herramienta admite archivos de audio de hasta 5 minutos de duración.
Paso 4: Trabaja con el resultado
Cada pista aparece como una pista independiente en tu línea de tiempo de arreglos. Pon en solo la pista vocal, recórtala, aplícale efectos, normalízala o empieza a construir a partir de ella, todo ello sin salir de la sesión.

A diferencia de las herramientas independientes de eliminación de voz en línea que te proporcionan un archivo para descargar y volver a importar a otro lugar, todo en Amped Studio permanece en la misma sesión. La pista que acabas de extraer ya es una pista de tu proyecto. Edita las pistas de audio, añade efectos, superpone nuevos instrumentos, empieza a esbozar un remix o una versión. Sin cambios de contexto, sin reimportaciones, sin interrupciones en tu flujo creativo.
Cómo funciona el aislamiento vocal con IA
Cada sonido de una grabación mezclada tiene una huella espectral distintiva: una forma característica a lo largo del espectro de frecuencias que cambia con el tiempo. Para entender cómo lee eso la IA, es útil saber qué es un espectrograma.
Un espectrograma es un mapa tridimensional del sonido: el tiempo discurre de izquierda a derecha, la frecuencia va de los graves en la parte inferior a los agudos en la parte superior, y la amplitud se codifica como brillo. Cada instrumento deja una huella diferente. Un bombo es un breve estallido en la parte baja del mapa. Un charles es un pico agudo en la parte superior. La voz humana traza un recorrido más complejo: resonancias armónicas, vibrato, la textura de las consonantes y la respiración. Lo suficientemente consistente como para poder aprenderse.

Los separadores de pistas de IA se entrenan con grandes conjuntos de datos de grabaciones multipista que consisten en mezclas completas emparejadas con sus pistas individuales. El modelo aprende a asociar formas espectrales y patrones de movimiento específicos con cada fuente. Si se le introduce una nueva pista, convierte el audio en un espectrograma, predice una máscara para cada instrumento y aplica esas máscaras para reconstruir las pistas. Sin filtrado. Sin ecualización. Puro reconocimiento de patrones.
Como la mayoría de las cosas en IA, la tecnología sigue evolucionando. Los modelos actuales más avanzados ejecutan un segundo análisis en paralelo: el audio no como una imagen, sino como lo que es físicamente —44 100 números por segundo, cada uno una instantánea de la forma de la onda—. Los filtros matemáticos escanean ese flujo en busca de las mismas huellas. Los dos flujos se ejecutan simultáneamente, y el modelo compara sus resultados entre sí en función de la fuente. Entre otras cosas, esto resuelve los problemas de fase a los que es propensa la separación basada exclusivamente en el espectrograma. El enfoque se denomina separación híbrida de fuentes, y actualmente es el estándar en las herramientas de separación de pistas de IA.
Aislamiento vocal con IA: el estado actual de la tecnología
Antes de que existiera la separación de pistas mediante IA, un método para extraer la voz era la cancelación de fase: invertir un canal estéreo y sumarlo al otro para cancelar cualquier elemento panoramizado hacia el centro. Ese enfoque se basaba en el hecho de que, en las mezclas comerciales, las voces suelen situarse justo en el centro del campo estéreo de la pista. En la práctica, las mezclas reales rara vez se ajustan a ese patrón tan perfectamente, y los resultados solían ser débiles, huecos o plagados de artefactos. La separación de pistas basada en IA supuso un avance espectacular.
Dicho esto, la extracción de voces mediante IA es una tecnología aún en desarrollo, y el resultado que produce no es lo mismo que disponer de partes instrumentales grabadas con claridad a partir de la sesión de grabación multipista original. Lo que se obtiene es la mejor estimación del modelo sobre la contribución de la voz a la mezcla. Para usos creativos personales, como crear una pista de karaoke o extraer una acapella para un mashup, la calidad es suficiente. Para el trabajo profesional de estudio que requiere un audio impecable, es posible que las voces extraídas por IA no siempre sean lo suficientemente limpias, aunque la diferencia se reduce a medida que se desarrollan los modelos de separación de pistas por IA.
Aislamiento vocal y derechos de autor
Los extractores vocales de IA están diseñados para uso personal, exploración creativa y aprendizaje. Crear una pista de karaoke para uno mismo, estudiar una interpretación vocal, experimentar con remezclas... todo eso entra de lleno dentro del uso personal.
Publicar o distribuir contenido que incluya pistas extraídas de grabaciones protegidas por derechos de autor es diferente. Lanzar un remix, distribuir un mashup o incorporar una pista vocal en un trabajo comercial requiere los derechos adecuados sobre el material original. Si tienes pensado lanzar o distribuir cualquier cosa basada en una voz extraída de la grabación de otra persona, asegúrate primero de que tienes los derechos para usarla.
Si alguna vez has tenido curiosidad por saber cómo suenan las voces de tu tema favorito por sí solas o cómo suena la canción sin ellas, este es el lugar por donde empezar. Súbelo a Amped Studio, ejecuta la separación y escucha el resultado.
FAQ
Utiliza un separador de pistas por IA como el AI Splitter de Amped Studio. Sube tu archivo de audio, selecciona una separación de 2 pistas y obtendrás una pista vocal y una pista instrumental, ambas apareciendo directamente en tu sesión de Amped Studio como pistas individuales, listas para editar o trabajar con ellas.
Sí. El AI Splitter de Amped Studio está disponible en el plan gratuito con un uso cada 24 horas. La separación de pistas en línea gratuita está disponible una vez cada 24 horas en el plan gratuito y de forma ilimitada en el plan Premium + AI.
Un extractor de acapella es una herramienta que separa la voz de la música y genera la voz por sí sola. La mayoría de las herramientas funcionan en ambos sentidos: conservar la voz y descartar la música, o conservar la música y descartar la voz. El mismo proceso de separación produce ambos resultados.
Los resultados dependen de la calidad de la grabación y del archivo de origen. Las voces de estudio limpias en arreglos escasos se separan bien. Las mezclas densas con mucha reverberación o armonías superpuestas son más difíciles. Los archivos fuente MP3 de baja velocidad de bits pueden introducir artefactos de compresión que se agravan durante la separación. Para la mayoría de aplicaciones creativas, el resultado es totalmente utilizable: no coincidirá con las pistas originales de la sesión multipista, pero para el uso diario la diferencia rara vez es un impedimento.
Mismo proceso, resultado diferente. La eliminación de la voz significa que se conserva la pista instrumental y se descarta la voz: la base de cualquier herramienta online de eliminación de voz o karaoke. La extracción de la voz significa que se conserva la voz y se descarta la música. Mismo archivo subido, misma separación, pistas diferentes.
Para uso personal y exploración creativa, sí. Si quieres publicar algo creado a partir de una voz extraída, tendrás que obtener los derechos del propietario de la grabación. Para los artistas independientes, contactar directamente suele ser la vía más sencilla. En el caso de los lanzamientos de grandes discográficas, el proceso solía ser menos sencillo, pero eso está cambiando. Spotify ha anunciado recientemente una herramienta de remezclas para fans en colaboración con Universal Music Group que permite a los oyentes crear y publicar versiones y remezclas de las canciones de los artistas participantes, y los ingresos se reparten con el artista original.
Empieza a crear beats y canciones en minutos. Sin experiencia necesaria — así de fácil.
Comenzar