Jak wyodrębnić wokal z utworu

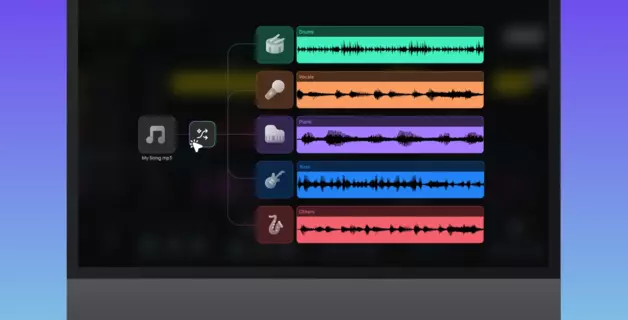
Aby wyodrębnić wokal z utworu (lub całkowicie go usunąć, aby uzyskać czystą wersję instrumentalną), należy skorzystać z narzędzia do usuwania wokalu opartego na sztucznej inteligencji — narzędzia, które analizuje cały miks i dzieli go na poszczególne ścieżki instrumentalne, zwane również ścieżkami stem. Prześlij plik, wybierz opcję podziału na 2 ścieżki, a otrzymasz dwa pliki wyjściowe: jeden zawierający wyłącznie wokal, a drugi pozostałe instrumenty (wersję instrumentalną).
W Amped Studio odbywa się to w ramach sesji. Wbudowane narzędzie AI Splitter pozwala wyodrębnić wokal online bez konieczności instalowania czegokolwiek — ścieżki pojawiają się bezpośrednio w projekcie jako ścieżki.
Czytaj dalej, aby dowiedzieć się więcej o tej technice, a także o:
- Najczęstszych zastosowań wyizolowanego wokalu
- Jak wyodrębnić wokal z utworu za pomocą narzędzia AI Splitter w Amped Studio
- Jak w rzeczywistości działa izolacja wokalu za pomocą sztucznej inteligencji
- Obecny stan technologii — i czego można oczekiwać od efektu końcowego
- Krótka uwaga na temat praw autorskich
Typowe zastosowania izolowanych wokali
Usuń wokal, zachowaj podkład
Najbardziej bezpośrednie zastosowanie każdego ekstraktora wokalu: pozbądź się wokalisty, zachowaj muzykę. Pozostaje czysty podkład instrumentalny — pełna aranżacja bez wokalisty na pierwszym planie.
W ten sposób powstają osobiste utwory karaoke, gdy nie ma oficjalnej wersji. W ten sposób muzycy wyodrębniają podkład z gotowego nagrania, aby ćwiczyć, nagrać cover lub wykorzystać go jako punkt odniesienia przy komponowaniu. Jeśli kiedykolwiek chciałeś mieć wersję karaoke piosenki, która jej nie ma — oto rozwiązanie.
Wyodrębnij ścieżkę a cappella z utworu do remiksowania, mashupów lub samplowania
Odwrotny kierunek: zachowaj wokal, odrzuć muzykę. Acapella to wyodrębniona ścieżka wokalna. Gdy już ją masz, możesz nałożyć ją na inny beat, transponować do nowej tonacji, wmieszać w mashup — lub pójść dalej i wyciąć z niej fragmenty, frazę tu, oddech tam, i wykorzystać te kawałki jako surowiec w zupełnie nowej produkcji. Niezależnie od tego, czy wykorzystujesz wokal w całości, czy w fragmentach, proces ekstrakcji acapelli jest taki sam: oddziel wokal od utworu, a następnie wykorzystaj go tam, gdzie wymaga tego projekt.
Jest to standardowa praktyka dla DJ-ów tworzących sety na żywo, producentów remiksujących bez dostępu do oryginalnych plików sesji oraz beatmakerów samplujących z istniejących nagrań.
Amped Studio jako narzędzie do wyodrębniania wokalu: krok po kroku
AI Splitter w Amped Studio działa całkowicie w przeglądarce — bez pobierania, bez instalacji. Ścieżki pojawiają się bezpośrednio w projekcie jako utwory, co oznacza, że wszystko, co dzieje się później — edycja, efekty, aranżacja, dodawanie nowych elementów — pozostaje w tym samym środowisku bez przełączania okien lub ponownego importowania plików.
Krok 1: Otwórz Amped Studio
Zaloguj się lub zarejestruj na stronie ampedstudio.com. Sesja otworzy się w przeglądarce w ciągu kilku sekund.
Krok 2: Kliknij „Podziel dowolny utwór”
Ekran powitalny zapewnia bezpośredni dostęp do AI Splitter. Kliknij go, aby otworzyć separator ścieżek.

Krok 3: Prześlij swój utwór i wybierz ścieżki
Przeciągnij plik audio lub wybierz go z biblioteki. W przypadku izolacji wokalu opcja 2 ścieżek zapewnia jedną ścieżkę wokalną i jedną instrumentalną. Jeśli chcesz uzyskać pełniejszy podział — z oddzielnymi ścieżkami perkusji, basu i fortepianu — wybierz 4 lub 5 ścieżek.
Narzędzie obsługuje pliki audio o długości do 5 minut.
Krok 4: Praca z wynikiem
Każda ścieżka pojawia się jako osobna ścieżka na osi czasu aranżacji. Włącz solo ścieżki wokalnej, przytnij ją, zastosuj efekty, znormalizuj lub zacznij budować wokół niej — wszystko to bez opuszczania sesji.

W przeciwieństwie do samodzielnych internetowych narzędzi do usuwania wokalu, które dostarczają plik do pobrania i ponownego zaimportowania w innym miejscu, w Amped Studio wszystko pozostaje w tej samej sesji. Właśnie wyodrębniony ślad jest już ścieżką w Twoim projekcie. Edytuj ścieżki audio, dodawaj efekty, nakładaj nowe instrumenty, zacznij szkicować remiks lub cover. Bez przełączania się między kontekstami, bez ponownego importowania, bez przerywania kreatywnego flow.
Jak działa izolacja wokalu za pomocą sztucznej inteligencji
Każdy dźwięk w zmiksowanym nagraniu ma swój charakterystyczny odcisk spektralny — charakterystyczny kształt w spektrum częstotliwości, który zmienia się w czasie. Aby zrozumieć, w jaki sposób sztuczna inteligencja to odczytuje, warto wiedzieć, czym jest spektrogram.
Spektrogram to trójwymiarowa mapa dźwięku: czas biegnie od lewej do prawej, częstotliwość od basów na dole do wysokich tonów na górze, a amplituda jest zakodowana jako jasność. Każdy instrument pozostawia inny ślad. Bęben basowy to krótki wybuch na dole mapy. Hi-hat to ostry skok na górze. Ludzki głos rysuje bardziej złożoną ścieżkę: rezonanse harmoniczne, vibrato, faktura spółgłosek i oddechu. Jest to na tyle spójne, że można się tego nauczyć.

Separatory ścieżek AI są szkolone na dużych zbiorach danych wielościeżkowych nagrań składających się z pełnych miksów w połączeniu z ich poszczególnymi ścieżkami. Model uczy się kojarzyć konkretne kształty spektralne i wzorce ruchowe z każdym źródłem. Wystarczy podać mu nowy utwór, a on przekształci dźwięk w spektrogram, przewidzi maskę dla każdego instrumentu i zastosuje te maski, aby zrekonstruować ścieżki. Bez filtrowania. Bez korektora. Czyste rozpoznawanie wzorców.
Jak większość rzeczy w AI, technologia ta nieustannie ewoluuje. Najbardziej zaawansowane obecne modele przeprowadzają równolegle drugą analizę: audio nie jako obraz, ale jako to, czym fizycznie jest — 44 100 liczb na sekundę, z których każda jest migawką kształtu fali. Filtry matematyczne skanują ten strumień w poszukiwaniu tych samych odcisków palców. Oba strumienie działają jednocześnie, a model porównuje ich wyniki w zależności od źródła. Rozwiązuje to między innymi problemy z fazą, na które podatne jest rozdzielanie oparte wyłącznie na spektrogramie. Podejście to nazywa się hybrydowym rozdzielaniem źródeł i jest obecnie standardem w narzędziach do rozdzielania ścieżek w AI.
Izolacja wokalu za pomocą sztucznej inteligencji: aktualny stan technologii
Zanim pojawiła się separacja ścieżek za pomocą sztucznej inteligencji, jedną z metod wyodrębniania wokalu było znoszenie fazowe: odwracanie jednego kanału stereo i sumowanie go z drugim w celu zniesienia wszystkiego, co zostało przesunięte do środka. Podejście to opierało się na fakcie, że wokale w komercyjnych miksach zazwyczaj znajdują się dokładnie w środku pola stereo utworu. W praktyce rzeczywiste miksy rzadko są tak idealnie dopasowane, a wyniki były często cienkie, puste lub pełne artefaktów. Separacja ścieżek oparta na sztucznej inteligencji była ogromnym krokiem naprzód.
Niemniej jednak ekstrakcja wokalu za pomocą sztucznej inteligencji to technologia wciąż rozwijająca się, a jej wynik nie jest taki sam, jak w przypadku czystych partii instrumentalnych z oryginalnej sesji nagrań wielościeżkowych. Efektem jest najlepsze oszacowanie modelu dotyczące wkładu wokalu w miks. Do osobistych zastosowań twórczych, takich jak tworzenie ścieżek karaoke lub wyodrębnianie partii a cappella do mashupów, jakość ta jest wystarczająca. W przypadku profesjonalnej pracy studyjnej wymagającej krystalicznie czystego dźwięku, wokale wyodrębnione przez AI mogą nie zawsze być wystarczająco czyste, choć różnica ta zmniejsza się wraz z rozwojem modeli separacji ścieżek opartych na sztucznej inteligencji.
Izolacja wokalu a prawa autorskie
Ekstraktory wokalu oparte na sztucznej inteligencji są tworzone do użytku osobistego, twórczej eksploracji i nauki. Tworzenie ścieżki karaoke dla siebie, studiowanie wykonania wokalnego, eksperymentowanie z remiksowaniem — wszystko to mieści się w ramach użytku osobistego.
Publikowanie lub dystrybucja treści zawierających wyodrębnione ścieżki z nagrań chronionych prawem autorskim to zupełnie inna sprawa. Wydanie remiksu, dystrybucja mashupu lub włączenie ścieżki wokalnej do pracy komercyjnej wymaga odpowiednich praw do materiału źródłowego. Jeśli planujesz wydać lub rozpowszechniać cokolwiek opartego na wokalu wyodrębnionym z cudzego nagrania, upewnij się najpierw, że masz prawa do jego wykorzystania.
Jeśli kiedykolwiek ciekawiło Cię, jak brzmi sam wokal z ulubionego utworu lub jak brzmi piosenka bez niego — to jest miejsce, od którego warto zacząć. Prześlij utwór do Amped Studio, uruchom funkcję rozdzielania i posłuchaj, co z tego wyjdzie.
FAQ
Użyj separatora ścieżek opartego na sztucznej inteligencji, takiego jak AI Splitter w Amped Studio. Prześlij plik audio, wybierz opcję podziału na 2 ścieżki, a otrzymasz ścieżkę wokalną i ścieżkę instrumentalną — obie pojawią się bezpośrednio w sesji Amped Studio jako osobne ścieżki, gotowe do edycji lub dalszej pracy.
Tak. AI Splitter od Amped Studio jest dostępny w planie darmowym z jednym użyciem na 24 godziny. Darmowa separacja ścieżek online jest dostępna raz na 24 godziny w planie darmowym i bez ograniczeń w planie Premium + AI.
Ekstraktor acapella to narzędzie, które oddziela wokal od muzyki i wyodrębnia sam głos. Większość narzędzi działa w obu kierunkach: zachowuje wokal i odrzuca muzykę lub zachowuje muzykę i odrzuca wokal. Ten sam proces separacji daje oba wyniki.
Wyniki zależą od jakości nagrania i pliku źródłowego. Czyste wokale studyjne w oszczędnych aranżacjach dzielą się dobrze. Gęste miksy z silnym pogłosem lub warstwowymi harmoniami są trudniejsze. Pliki źródłowe MP3 o niskiej przepływności mogą powodować artefakty kompresji, które nasilają się podczas separacji. W większości zastosowań kreatywnych wynik jest w pełni użyteczny — nie będzie on odpowiadał oryginalnym ścieżkom sesji wielościeżkowej, ale w codziennym użytkowaniu różnica ta rzadko stanowi przeszkodę.
Ten sam proces, ale inny wynik. Usunięcie wokalu oznacza, że zachowujesz instrumenty, a pozbywasz się wokalu — to podstawa każdego internetowego narzędzia do usuwania wokalu lub karaoke. Wyodrębnienie wokalu oznacza, że zachowujesz wokal, a pozbywasz się muzyki. To samo przesłanie, ta sama separacja, różne ścieżki.
Do użytku osobistego i twórczych eksperymentów – tak. Jeśli chcesz wydać utwór oparty na wyodrębnionym wokalu, musisz uzyskać zgodę właściciela nagrania. W przypadku niezależnych artystów najprostszym rozwiązaniem jest często bezpośredni kontakt. W przypadku wydawnictw dużych wytwórni proces ten tradycyjnie był mniej prosty, ale to się zmienia. Spotify ogłosiło niedawno we współpracy z Universal Music Group narzędzie do tworzenia remiksów przez fanów, które pozwala słuchaczom tworzyć i wydawać covery oraz remiksy utworów uczestniczących w programie artystów, a dochody są dzielone z oryginalnym artystą.
Zacznij tworzyć bity i piosenki w kilka minut. Żadnego doświadczenia — to takie proste.
Zacznij