So isoliert man den Gesang aus einem Song

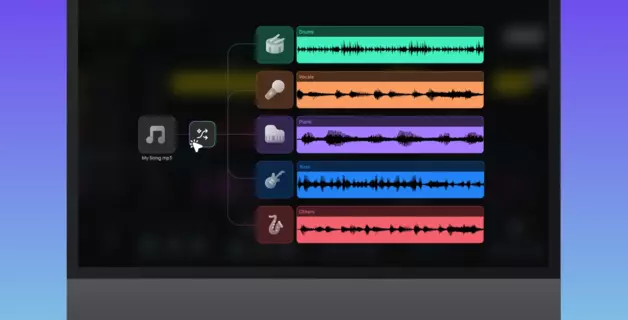
Um den Gesang aus einem Song herauszufiltern (oder ihn ganz zu entfernen, um eine reine Instrumentalversion zu erhalten), nutzt man einen KI-Gesangsentferner – ein Tool, das den gesamten Mix analysiert und ihn in einzelne Instrumentenspuren, sogenannte Stems, aufteilt. Lade deine Datei hoch, wähle eine 2-Stem-Aufteilung und du erhältst zwei Ausgabespuren: eine nur mit dem Gesang, eine mit dem Rest (dem Instrumental).
In Amped Studio geschieht dies direkt in deiner Session. Mit dem integrierten AI-Splitter-Tool kannst du Gesang online isolieren, ohne etwas installieren zu müssen – die Stems erscheinen direkt in deinem Projekt als Spuren.
Lies weiter, um mehr über diese Technik zu erfahren, sowie über:
- Die gängigsten Verwendungszwecke für isolierten Gesang
- Wie man mit dem AI Splitter von Amped Studio Gesang aus einem Song extrahiert
- Wie die KI-Gesangsextraktion unter der Haube tatsächlich funktioniert
- Wo die Technologie derzeit steht – und was du vom Ergebnis erwarten kannst
- Ein kurzer Hinweis zum Urheberrecht
Häufige Verwendungszwecke für isolierte Gesangsstimmen
Gesang entfernen, Instrumental behalten
Die direkteste Anwendung eines Gesangsextraktors: den Sänger entfernen, die Musik behalten. Was übrig bleibt, ist ein sauberes Instrumental – das vollständige Arrangement ohne den Leadgesang darüber.
So entstehen persönliche Karaoke-Tracks, wenn keine offizielle Version existiert. Auf diese Weise extrahieren Musiker auch einen Backing-Track aus einer fertigen Aufnahme, um dazu zu proben, ein Cover aufzunehmen oder ihn als kompositorische Vorlage zu nutzen. Wenn du schon immer eine Karaoke-Version eines Songs haben wolltest, für den es keine gibt – hier ist die Lösung.
Extrahieren Sie einen A-cappella-Track aus einem Song für Remixe, Mashups oder Sampling
Die umgekehrte Vorgehensweise: Behalte den Gesang, entferne die Musik. Ein A-cappella ist die isolierte Gesangsspur für sich allein. Sobald du sie hast, kannst du sie über einen anderen Beat legen, in eine neue Tonart transponieren, in ein Mashup einbinden – oder noch einen Schritt weiter gehen und Fragmente daraus ausschneiden, hier eine Phrase, dort einen Atemzug, und diese Teile als Rohmaterial für eine völlig neue Produktion verwenden. Ob du den Gesang nun als Ganzes oder in Teilen verwendest, der Arbeitsablauf beim Extrahieren des A-cappella-Tracks ist derselbe: Trenne den Gesang vom Song und nutze ihn dann ganz nach den Anforderungen deines Projekts.
Dies ist gängige Praxis für DJs, die Live-Sets erstellen, für Produzenten, die ohne Zugriff auf die Original-Session-Dateien remixen, und für Beatmaker, die aus bestehenden Aufnahmen samplen.
Amped Studio als Vocal-Extractor: Schritt für Schritt
Der AI Splitter von Amped Studio läuft vollständig in deinem Browser – kein Download, keine Installation. Die Stems erscheinen direkt in deinem Projekt als Spuren, was bedeutet, dass alles, was als Nächstes passiert – Bearbeiten, Effekte, Arrangieren, Hinzufügen neuer Elemente – in derselben Umgebung bleibt, ohne dass du zwischen Fenstern wechseln oder Dateien neu importieren musst.
Schritt 1: Öffne Amped Studio
Melden Sie sich an oder registrieren Sie sich auf ampedstudio.com. Die Session öffnet sich innerhalb von Sekunden in Ihrem Browser.
Schritt 2: Klicken Sie auf „Beliebigen Song aufteilen“
Über den Begrüßungsbildschirm gelangst du direkt zum AI Splitter. Klicke darauf, um den Stem-Separator zu öffnen.

Schritt 3: Lade deinen Track hoch und wähle deine Stems aus
Zieh deine Audiodatei per Drag & Drop hinein oder wähle sie aus deiner Bibliothek aus. Für die Gesangsisolierung bietet dir die 2-Stem-Option einen Gesangs-Stem und einen Instrumental-Stem. Wenn du eine umfassendere Aufteilung wünschst – also auch Schlagzeug, Bass und Klavier getrennt –, wähle 4 oder 5 Stems.
Das Tool unterstützt Audiodateien mit einer Länge von bis zu 5 Minuten.
Schritt 4: Bearbeite das Ergebnis
Jeder Stem erscheint als separate Spur in deiner Arrangement-Timeline. Schalte den Vocal-Stem solo, trimme ihn, wende Effekte an, normalisiere ihn oder baue darauf auf – alles, ohne die Session zu verlassen.

Im Gegensatz zu eigenständigen Online-Tools zum Entfernen von Gesang, die dir eine Datei zum Herunterladen und erneuten Importieren an anderer Stelle liefern, bleibt in Amped Studio alles in derselben Session. Der soeben extrahierte Stem ist bereits eine Spur in deinem Projekt. Bearbeite die Audiospuren, füge Effekte hinzu, überlagere sie mit neuen Instrumenten, beginne mit der Skizze eines Remixes oder eines Covers. Kein Kontextwechsel, kein erneutes Importieren, keine Unterbrechung deines kreativen Flusses.
So funktioniert die KI-Gesangsextraktion
Jeder Ton in einer gemischten Aufnahme hat einen eindeutigen spektralen Fingerabdruck – eine charakteristische Form über das Frequenzspektrum, die sich im Laufe der Zeit verändert. Um zu verstehen, wie KI das liest, ist es hilfreich zu wissen, was ein Spektrogramm ist.
Ein Spektrogramm ist eine dreidimensionale Karte des Klangs: Die Zeit verläuft von links nach rechts, die Frequenz vom Bass unten bis zu den Höhen oben, die Amplitude wird als Helligkeit kodiert. Jedes Instrument hinterlässt eine andere Spur. Eine Kick-Drum ist ein kurzer Ausbruch unten auf der Karte. Eine Hi-Hat ist ein scharfer Ausschlag ganz oben. Eine menschliche Stimme zeichnet einen komplexeren Verlauf nach: harmonische Resonanzen, Vibrato, die Textur von Konsonanten und Atem. Konsistent genug, um gelernt zu werden.

KI-Stem-Separatoren werden anhand großer Datensätze von Mehrspuraufnahmen trainiert, die aus vollständigen Mixes und den dazugehörigen einzelnen Stems bestehen. Das Modell lernt, bestimmte Spektralformen und Bewegungsmuster mit jeder Quelle zu verknüpfen. Gibt man ihm einen neuen Track, wandelt es das Audio in ein Spektrogramm um, sagt eine Maske für jedes Instrument voraus und wendet diese Masken an, um die Stems zu rekonstruieren. Kein Filtern. Kein EQ. Reine Mustererkennung.
Wie die meisten Dinge in der KI entwickelt sich auch diese Technologie ständig weiter. Die derzeit fortschrittlichsten Modelle führen parallel eine zweite Analyse durch: Das Audio wird nicht als Bild betrachtet, sondern als das, was es physikalisch ist – 44.100 Zahlen pro Sekunde, jede davon ein Momentaufnahme der Wellenform. Mathematische Filter scannen diesen Datenstrom auf der Suche nach denselben Fingerabdrücken. Die beiden Ströme laufen gleichzeitig, und das Modell wägt ihre Ergebnisse je nach Quelle gegeneinander ab. Dies behebt unter anderem Phasenprobleme, für die eine rein spektrogrammbasierte Trennung anfällig ist. Der Ansatz wird als hybride Quellentrennung bezeichnet und ist mittlerweile der Standard bei KI-Tools zur Stemmtrennung.
KI-Gesangsisolierung: Der aktuelle Stand der Technik
Bevor es die KI-Stem-Separation gab, war eine Methode zur Extraktion von Gesang die Phasenauslöschung: Dabei wurde ein Stereokanal invertiert und mit dem anderen summiert, um alles auszulöschen, was in die Mitte gepannt war. Dieser Ansatz basierte auf der Tatsache, dass Gesang in kommerziellen Mixen typischerweise genau in der Mitte des Stereofeldes des Tracks liegt. In der Praxis entsprechen reale Mixe dieser Idealvorstellung jedoch selten, und die Ergebnisse klangen oft dünn, hohl oder waren voller Artefakte. Die KI-basierte Stem-Separation war ein dramatischer Fortschritt.
Allerdings ist die KI-basierte Gesangsextraktion eine Technologie, die sich noch in der Entwicklung befindet, und das Ergebnis entspricht nicht den sauber aufgenommenen Instrumentenspuren aus der ursprünglichen Mehrspuraufnahme. Was dabei herauskommt, ist die beste Schätzung des Modells darüber, welchen Beitrag der Gesang zum Mix geleistet hat. Für persönliche kreative Zwecke wie die Erstellung eines Karaoke-Tracks oder die Extraktion eines A-cappella-Parts für ein Mashup ist die Qualität ausreichend. Für professionelle Studioarbeit, die makellosen Klang erfordert, sind KI-extrahierte Vocals möglicherweise nicht immer sauber genug, auch wenn sich diese Lücke mit der Weiterentwicklung der KI-Stem-Separationsmodelle verringert.
Gesangsisolierung und Urheberrecht
KI-Gesangsextraktoren sind für den persönlichen Gebrauch, kreative Erkundungen und zum Lernen konzipiert. Einen Karaoke-Track für sich selbst zu erstellen, eine Gesangsdarbietung zu studieren, mit Remixen zu experimentieren – all das fällt eindeutig unter den persönlichen Gebrauch.
Die Veröffentlichung oder Verbreitung von Inhalten, die extrahierte Stems aus urheberrechtlich geschützten Aufnahmen enthalten, ist etwas anderes. Die Veröffentlichung eines Remixes, die Verbreitung eines Mashups oder die Einbindung eines Vocal-Stems in kommerzielle Arbeiten erfordert die entsprechenden Rechte an dem zugrunde liegenden Material. Wenn du vorhast, etwas zu veröffentlichen oder zu verbreiten, das auf einem aus der Aufnahme eines anderen extrahierten Vocal basiert, stelle sicher, dass du die Nutzungsrechte dafür hast.
Wenn du schon immer einmal wissen wolltest, wie der Gesang eines Lieblingssongs für sich allein klingt oder wie der Song ohne ihn klingt – hier ist der richtige Ort, um damit anzufangen. Lade ihn in Amped Studio hoch, führe die Trennung durch und höre dir das Ergebnis an.
FAQ
Verwende einen KI-Stem-Separator wie den AI Splitter von Amped Studio. Lade deine Audiodatei hoch, wähle eine 2-Stem-Trennung aus, und du erhältst einen Gesangs-Stem und einen Instrumental-Stem – beide erscheinen direkt in deiner Amped Studio-Session als einzelne Spuren, bereit zur Bearbeitung oder zum Weiterverarbeiten.
Ja. Der AI Splitter von Amped Studio ist im kostenlosen Tarif mit einer Nutzung pro 24 Stunden verfügbar. Die kostenlose Online-Stem-Trennung ist im kostenlosen Tarif einmal pro 24 Stunden und im Premium + AI-Tarif unbegrenzt verfügbar.
Ein A-cappella-Extraktor ist ein Tool, das den Gesang von der Musik trennt und die Stimme separat ausgibt. Die meisten Tools arbeiten in beide Richtungen: Sie behalten den Gesang und verwerfen die Musik oder behalten die Musik und verwerfen den Gesang. Der gleiche Trennungsprozess erzeugt beide Ergebnisse.
Die Ergebnisse hängen von der Qualität der Aufnahme und der Quelldatei ab. Saubere Studiostimmen in spärlichen Arrangements lassen sich gut trennen. Dichte Mixe mit starkem Hall oder mehrstimmigen Harmonien sind schwieriger. MP3-Quelldateien mit niedriger Bitrate können Kompressionsartefakte verursachen, die sich bei der Trennung verstärken. Für die meisten kreativen Anwendungen ist das Ergebnis voll brauchbar – es entspricht zwar nicht den ursprünglichen Multitrack-Session-Stems, aber für den täglichen Gebrauch ist der Unterschied selten gravierend.
Gleicher Prozess, unterschiedliches Ergebnis. Gesangsentfernung bedeutet, dass man die Instrumentalbegleitung behält und den Gesang entfernt – die Grundlage jedes Online-Gesangsentferners oder Karaoke-Tools. Gesangsextraktion bedeutet, dass man den Gesang behält und die Musik entfernt. Gleicher Upload, gleiche Trennung, unterschiedliche Stems.
Für den persönlichen Gebrauch und kreative Experimente, ja. Wenn du etwas veröffentlichen möchtest, das auf einem extrahierten Gesang basiert, musst du die Rechte mit dem Eigentümer der Aufnahme klären. Für unabhängige Künstler ist es oft am einfachsten, sich direkt an ihn zu wenden. Bei Veröffentlichungen großer Labels war der Prozess bisher weniger unkompliziert, aber das ändert sich gerade. Spotify hat kürzlich gemeinsam mit der Universal Music Group ein Fan-Remix-Tool angekündigt, mit dem Hörer Cover und Remixe der Titel teilnehmender Künstler erstellen und veröffentlichen können, wobei die Einnahmen an den ursprünglichen Künstler zurückfließen.
Beginne in Minuten, Beats und Songs zu erstellen. Keine Erfahrung nötig — so einfach ist das.
Jetzt starten