Reihenfolge der Vokalketten: Wie man eine grundlegende Vokalkette in Amped Studio aufbaut


Cleanup-EQ → Kompression → De-Essing → Klangformungs-EQ → Sättigung → Delay → Hall → Limiter. Das ist die übliche Reihenfolge bei der Effektkette für Gesang.
Diese Reihenfolge ist nicht nur Tradition – sie entspricht der Position, an der jeder Effekt in der Kette stehen muss, um richtig zu funktionieren. Das liegt daran, dass jeder Effekt in der Kette das Ausgangssignal aller vorangegangenen Effekte verarbeitet und verschiedene Effekttypen das Signal auf unterschiedliche Weise formen. Wenn du die Kompression vor den Cleanup-EQ schaltest, hat der Kompressor mit Frequenzen zu kämpfen, auf die er eigentlich nicht reagieren sollte. Wenn du den Hall in der Mitte der Kette platzierst, verarbeiten alle nachfolgenden Effekte sowohl den Gesang als auch dessen gesamte Hallschwänze.
Dieser Leitfaden führt dich Schritt für Schritt durch die Reihenfolge der Vocal-Effektkette, erklärt, warum jeder Effekt an seiner Stelle sitzt, und zeigt, wie du die Kette in Amped Studio aufbaust. Du wirst nicht immer jeden Effekt benötigen – die Kette zeigt, wo jeder einzelne hingehört, wenn du ihn verwendest. Hör dir zuerst deinen Gesang im Mix an und füge dann hinzu, was er tatsächlich benötigt.
Was ist eine Vocal-Kette?
Eine Vocal-Kette ist eine Abfolge von Audioeffekten, die auf eine Vocal-Spur gelegt werden, wobei das Signal nacheinander durch jeden Effekt fließt. Der erste Effekt bearbeitet den trockenen Gesang. Der zweite Effekt bearbeitet das, was der erste ausgibt. Der dritte bearbeitet das, was der zweite erzeugt hat – und so weiter entlang der Kette. Jeder Effekt sieht nur das, was der vorherige an ihn weitergeleitet hat, weshalb die Reihenfolge genauso wichtig ist wie die Einstellungen.
Eine gut abgestimmte Vocal-Kette ist ein wesentlicher Bestandteil des Mixings. Ihre Aufgabe ist es, den Gesang harmonisch in den Kontext der anderen Instrumente einzubetten – mit mehr Klarheit, kontrollierter Dynamik und Geschmeidigkeit. Delay und Reverb verleihen dieser Arbeit eine kreative Dimension: Indem sie dem Gesang ein räumliches Element hinzufügen, können sie die ursprüngliche Gesangsdarbietung erheblich verändern.
Warum die Reihenfolge der Vocal-Kette wichtig ist
Wenn du Effekte nacheinander auf deine Gesangsspur legst, bedeutet das, dass der Originalklang plus Effekt als Eingangssignal an den nächsten Effekt weitergeleitet wird. Das macht die Reihenfolge der Effekte sehr wichtig. Auf Korrektureffekte, die das entfernen, was nicht da sein sollte, folgt eine Kompression, die das Gesamtsignal kontrolliert (oder ausgleicht), und darauf folgen additive Effekte, die dem Signal Verzierungen hinzufügen oder sein Timbre kreativ verbessern.
Nehmen wir das tiefe Ende einer Gesangsaufnahme – alles unterhalb von 80–100 Hz. Eine menschliche Stimme erzeugt in diesem Bereich normalerweise keine nützlichen Informationen, aber das Mikrofon nimmt viel auf: Raumgeräusche, Poppgeräusche bei „p“- und „b“-Lauten, Hintergrundgeräusche. Schneidet man diese Frequenzen mit einem Hochpassfilter (Cleanup-Equalizer) vor dem Kompressor ab, reagiert der Kompressor sauber auf den Gesang. Wenn du diesen Cleanup-EQ stattdessen hinter den Kompressor schaltest, hat der Kompressor mit dem tiefen Rumpeln zu kämpfen, das dein Mikrofon eingefangen hat, oder reagiert übermäßig auf Poppspitzen – und ringt damit, was der Cleanup-EQ eigentlich bereinigen soll. Gleiche Effekte, unterschiedliche Reihenfolge – unterschiedliche Ergebnisse.
Tipp: Nimm deinen Gesang zuerst sauber auf. Bearbeite ihn nicht während der Aufnahme. Nimm den trockenen Gesang auf und baue dann deine Kette beim Abmischen auf. Audioeffekte in DAWs sind nicht-destruktiv, sodass du jede Entscheidung später ändern kannst – aber nur, wenn die zugrunde liegende Aufnahme unberührt bleibt.
Die Reihenfolge der Vocal-Kette, Schritt für Schritt
Die vollständige grundlegende Gesangskette (mit Hinweisen dazu, wie oft du die einzelnen Effekte benötigst) sieht wie folgt aus:
- Equalizer (Bereinigung) – subtraktive Absenkungen, um problematische Frequenzen zu entfernen (unverzichtbar)
- Kompressor – Dynamik ausgleichen (unverzichtbar)
- De-Esser – Zischlaute dämpfen (oft erforderlich)
- Equalizer (Klangformung) – Präsenz und Luft hinzufügen (oft, mit Zurückhaltung)
- Sättigung – harmonische Fülle (situationsabhängig)
- Delay – Tiefe und rhythmische Spannung (situationsabhängig, kreativ)
- Reverb – räumliche Platzierung (in der Regel vorhanden)
- Limiter – abschließende Spitzenwertbegrenzung (Sicherheitsnetz)
In dieser Vocal-Effektkette kommen drei Equalizer-Instanzen an drei verschiedenen Stellen zum Einsatz, die jeweils eine andere Aufgabe erfüllen: Frequenzbereinigung, De-Essing, Klangformung.
Schritt 1 – Equalizer (Bereinigung)
Der erste Effekt in den meisten Vocal-Ketten ist ein Cleanup-EQ. Seine Aufgabe ist subtraktiv: Er filtert problematische Frequenzen heraus, bevor andere Effekte sie verstärken.
Drei typische Maßnahmen:
- Hochpassfilter bei 80–100 Hz, um tieffrequentes Rumpeln, Vibrationen des Mikrofonständers und den Nahbesprechungseffekt zu entfernen
- Reduzieren Sie Trübungen im Bereich von 200–400 Hz mit einer Absenkung von 3–6 dB und einem mäßig breiten Q
- Notch-Filter im Bereich von 500 Hz–1 kHz mit schmalem Q und einer Absenkung von 3–6 dB, um den störenden Frequenzbereich zu beseitigen – zunächst mit einer Anhebung scannen, um die störende Frequenz zu finden

Warum zuerst: Das Entfernen problematischer Frequenzen vor der Kompression bedeutet, dass der Kompressor auf den Gesang selbst reagiert und nicht auf Trübungen oder Brummen.
Schritt 2 – Kompressor
Kompression gleicht die Dynamik aus. Die menschliche Stimme ist in ihrer Lautstärke sehr ungleichmäßig, und der Kompressor zieht leise Passagen und laute Spitzen auf ein gleichmäßigeres Niveau, sodass jedes Wort im Mix klar zur Geltung kommt.
Ausgangseinstellungen für einen Gesang:
- Ratio: 3:1 bis 4:1
- Attack: 15–30 ms – langsam genug, damit Konsonanten durchkommen
- Release: 50–100 ms
- Threshold: So einstellen, dass an den lautesten Stellen eine Pegelabsenkung von 3–6 dB erzielt wird
- Makeup-Gain (Post-Gain): Den Gesamtpegel wieder anheben, nachdem die Kompression die Spitzenwerte abgesenkt hat

Warum hier: Der Cleanup-EQ hat die schlimmsten Frequenzprobleme beseitigt, sodass die Kompression nun sauber auf den Gesang reagiert, anstatt mit Schlamm oder Rumpeln zu kämpfen.
Schritt 3 – De-Esser
Ein De-Esser ist ein spezieller Vocal-Equalizer, der dazu dient, schrille Zischlaute zu bändigen, die beim Aussprechen von „s“, „sh“ und „t“ entstehen. Es gibt spezielle Plugins, die genau für diese Aufgabe entwickelt wurden, aber jeder Equalizer mit schmaler Q-Steuerung kann diese Aufgabe gut bewältigen. In Amped Studio verwenden wir einen zweiten Equalizer für diese Aufgabe:
- Finde die scharfe Frequenz. Zischlaute liegen normalerweise zwischen 5 und 10 kHz. Führe während der Wiedergabe des Gesangs einen schmalen Boost über diesen Bereich und höre auf die Stelle, an der die Schärfe unangenehm wird – dort setzt die Dämpfung an. Konzentriere dich außerdem speziell auf Wörter und Phrasen mit den schärfsten Zischlauten, um die Frequenzen zu finden, die behandelt werden müssen.
- Schmaler Q-Faktor, 3–6 dB Absenkung bei der störenden Frequenz.
- Eine statische Absenkung funktioniert bei den meisten Gesangsaufnahmen. Wenn nur bestimmte Phrasen schrille Zischlaute aufweisen, kann die Absenkung automatisiert werden, aber in den meisten Fällen reicht eine feste Absenkung aus.

Warum nach der Kompression: In den meisten Fällen werden Zischlaute erst nach dem Kompressor so deutlich, dass sie korrigiert werden müssen. Das De-Essing muss nach dem Kompressor erfolgen, um das zu zähmen, was der Kompressor verstärkt hat.
Tipp: Mische den Gesang im Kontext, nicht nur im Solo. Solo ist nützlich, um bei der Anpassung einer bestimmten Einstellung feine Details zu hören, aber jede Entscheidung muss im Kontext des gesamten Arrangements angehört werden.
Schritt 4 – Equalizer (Klangformung)
Die dritte Equalizer-Instanz ist additiv – Anhebungen, die die besten Eigenschaften des Gesangs hervorheben, nachdem Probleme beseitigt und die Dynamik kontrolliert wurden.
Zwei typische Vorgehensweisen:
- Anhebung um 1–2 dB bei 2–5 kHz für Präsenz und Klarheit – hier setzt sich der Gesang im Mix durch
- Sanfter High-Shelf bei 10–12 kHz für Luftigkeit – eine subtile Anhebung, die den oberen Frequenzbereich öffnet, ohne dass es schrill klingt

Warum nach dem De-Essing: Die Klangformung fügt Energie in denselben Frequenzbereichen hinzu, in denen Zischlaute auftreten. Wenn du vor dem De-Essing anhebst, verstärkst du die Schärfe, die du gerade bekämpfen willst. Wenn du danach anhebst, hebst du die weiche, kontrollierte Version der hohen Frequenzen an.
Schritt 5 – Sättigung
Sättigung sorgt für harmonischen Reichtum (oft als „Wärme“ bezeichnet) – zusätzliche Frequenzanteile, die durch den Effekt selbst erzeugt werden. Bei Gesang lässt sie die Stimme bei gleicher Fader-Lautstärke lauter und präsenter wirken, wenn sie subtil eingesetzt wird. Anders als bei der Gitarre, wo der Drive den Klang ausmacht, ist Sättigung bei Gesang eher eine Würze – gerade genug, um das Signal zu färben, ohne dass der Hörer es wirklich bemerkt.
In Amped Studio lässt sich dies gut mit dem Distortion-Gerät bewerkstelligen. Beginne mit dem Preset „Purr“, das einen sanften, transparenten Charakter bietet, der gut zu Gesang passt, und passe die Einstellungen von dort aus an:
- Pre Gain – der wichtigste Regler. Drehen Sie ihn langsam auf, bis sich der Gesang etwas fülliger anfühlt, und dann wieder zurück, bis der Effekt im Solo kaum noch wahrnehmbar ist
- Tone vollständig aufgedreht – das Zurückdrehen von Tone dämpft die Höhen und verdunkelt den Gesang
- Boost aus oder auf niedrigster Stufe – nützlich bei Gitarren, bei Gesang wirkt es zu aggressiv
- Mix auf 100 %; Intensity und Feedback nach Geschmack

Warum hier: Der EQ zur Klangformung hat die richtigen Frequenzen angehoben. Die Sättigung fügt nun speziell diesen Frequenzen harmonische Anteile hinzu und verstärkt so die Präsenz und Luftigkeit, die du gerade angehoben hast.
Tipps zur Sättigung:
- Verschiedene Sättigungswerkzeuge bieten unterschiedliche Regler, aber der Eingangsgain ist fast immer der Parameter, der die hörbare Wirkung erzielt
- Sättigung lässt sich leicht übertreiben – wenn du sie im Solo als deutlichen Effekt hörst, reduziere den Eingangsgewinn, bis sie verschwindet, und erhöhe ihn dann nur ganz leicht
- Nicht jeder Gesang benötigt Sättigung. Ein Gesang, der im Mix bereits im Vordergrund steht, sollte in diesem Schritt am besten unberührt bleiben
Schritt 6 – Delay
Delay fügt rhythmische Echos und ein Gefühl von Räumlichkeit hinzu. Es dient eher der Gestaltung als der Korrektur – nützlich bei Hooks, am Ende des letzten Wortes einer Phrase und in Refrains.
Ausgangseinstellungen:
- Delay-Zeit: Nach Gehör einstellen, bis sich die Echos dem Puls des Songs angepasst anfühlen
- Feedback: 15–25 % – genug für ein paar hörbare Wiederholungen, nicht genug, um in einen langen Nachhall überzugehen
- Mix: konservativ – siehe den Tipp unten

Warum vor dem Reverb: Delay erzeugt diskrete, hörbare Echos. Reverb erzeugt einen Nachhall aus räumlicher Klangfülle nach dem Ton. Wenn du Delay vor dem Reverb platzierst, verarbeitet der Reverb auch die Echos.
Tipp: Die Delay-Zeit ist eher eine kreative Entscheidung als eine Regel. Die richtige Einstellung hängt vom Gesang, dem Arrangement und davon ab, was gut zum Rest des Tracks passt – probiere verschiedene Zeiteinstellungen oder rhythmische Unterteilungen aus und lass dein Gehör entscheiden, welche sich für dein Arrangement richtig anfühlt.
Schritt 7 – Hall
Reverb versetzt den Gesang in eine räumliche Umgebung – einen Raum, eine Halle, eine Platte. Es bestimmt, woher der Gesang zu kommen scheint.
Die meisten Hall-Effekte verfügen über Voreinstellungen für verschiedene Räume. Wähle eine, die zum Track passt – intime Räume für nah aufgenommene, trockene Vocals, größere Räume für Balladen und offene Arrangements – und forme sie dann mit drei gängigen Reglern:
- Size – wie groß sich der Raum anfühlt; der Regler, der nach dem Preset den Charakter am stärksten bestimmt
- Damp – wie viel Hochfrequenz der Nachhall behält; mehr Dämpfung sorgt für einen dunkleren Nachhall, der besser hinter dem Gesang sitzt
- Mix – das Wet/Dry-Verhältnis; halte es niedrig, bei etwa 10–20 %, damit der Hall Raum schafft, ohne den trockenen Gesang zu übertönen

Warum an vorletzter Stelle: Der Hall definiert den Raum, in dem sich der Gesang befindet. Alles vor dem Hall prägt, wie der Gesang klingt; der Hall entscheidet, wo sich dieser Gesang befindet.
Tipp: Hall verdient seinen Platz kreativ gesehen, wenn er automatisiert wird, nicht wenn er einmal eingestellt und dann vergessen wird. Halte den Grundmix konservativ – 10–20 % – und erhöhe dann den Wet-Pegel an bestimmten Stellen: beim letzten Wort einer Phrase, bei einem Adlib, beim Übergang in den Refrain. Diese Hall-Einsätze schaffen Raum an musikalischen Höhepunkten, ohne den Gesang an anderen Stellen zu übertönen.
Schritt 8 – Limiter
Der Limiter ist eine Sicherheitsvorrichtung. Er formt den Gesang nicht kreativ – er verhindert, dass gelegentliche laute Spitzen im Master-Bus übersteuern.
Zwei Regler übernehmen die wesentliche Arbeit, unabhängig davon, welchen Limiter du verwendest:
- Threshold (manchmal auch als Ceiling bezeichnet) – der Pegel, den das Signal nicht überschreiten darf. Stelle ihn auf einen Wert zwischen -0,5 und -1 dB ein – so werden die lautesten Gesangspitzen abgefangen, ohne normale Phrasen zu beeinträchtigen
- Release – wie schnell der Limiter nach dem Abfangen eines Peaks wieder nachlässt. Belassen Sie ihn auf der Standardeinstellung, es sei denn, Sie hören ein Pumpen; schnelleres Release bei lebhaften Gesangspassagen, langsameres bei lang gehaltenen

Warum als Letztes: Alles vor diesem Punkt hat den Gesang kreativ geformt. Der Limiter dient ausschließlich dazu, Clipping zu verhindern. Platzieren Sie ihn an einer anderen Stelle in der Kette, und Sie begrenzen entweder zu früh – wodurch Sie die Dynamik zunichte machen, die Ihr Kompressor aufgebaut hat – oder lassen Peaks zum Master durch.
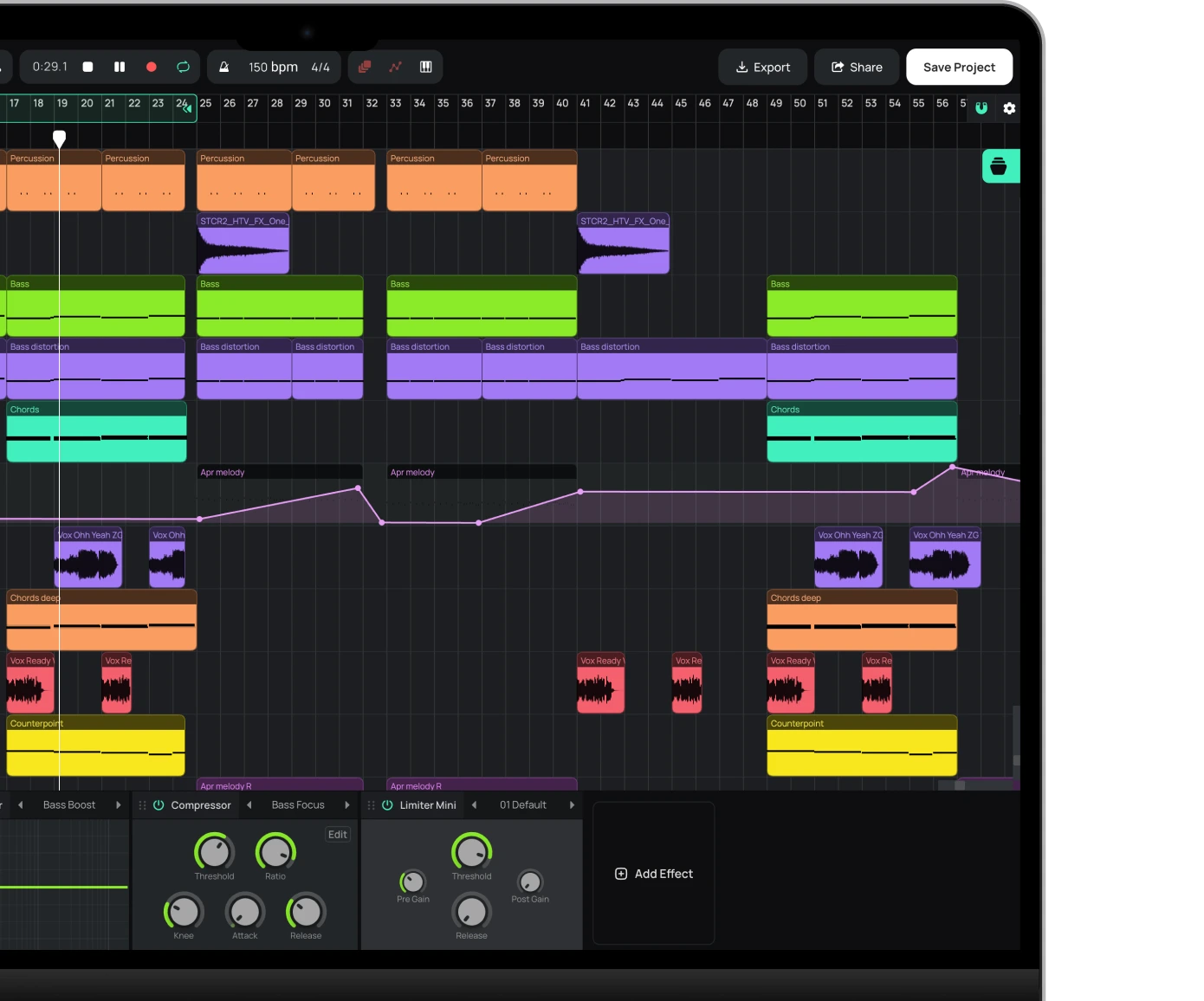
Aufbau der Kette in Amped Studio
In Amped Studio werden Effekte im Device Panel am unteren Rand des Studios hinzugefügt. Jedes Gerät in der Kette verarbeitet das Signal von links nach rechts – der Effekt ganz links kommt zuerst, der ganz rechts zuletzt.
So baust du die Gesangssignalkette in Amped Studio auf:
Wähle die Gesangsspur im Arrangement aus.
Öffne das Geräte-Panel durch Doppelklick auf den Gesangsaufnahmeclip.
Klicken Sie auf „Add Effect“ und wählen Sie „Equalizer“ – Ihren Cleanup-EQ. Nehmen Sie die EQ-Anpassungen vor (Absenkung der tiefen Frequenzen, Absenkung der Boxigkeit in den unteren Mitten). Stellen Sie sicher, dass die Solo-Funktion der Gesangsspur deaktiviert ist, und hören Sie sich Ihre Anpassungen im Kontext des gesamten Mixes an.
Klicken Sie erneut auf „Effekt hinzufügen“ und fügen Sie einen Kompressor hinzu. Nehmen Sie die Anpassungen gemäß der obigen Anleitung vor, während Sie den Mix im Gesamtkontext anhören.
Füge weitere Effekte der Reihe nach hinzu – aber nur diejenigen, die dein Gesang tatsächlich benötigt. Denke daran, dass einige Effekte wie tonformender EQ, Sättigung, Hall und Delay optional sind und von deiner Gesangsaufnahme und dem Song abhängen.

Die Kette ist nicht-destruktiv. Deaktiviere jeden Effekt über den Power-Button in seiner Kopfzeile, ordne die Effekte per Drag & Drop neu an oder entferne und ersetze sie, ohne die zugrunde liegende Aufnahme zu beeinträchtigen. Baue zunächst die vollständige Kette auf und schalte dann einzelne Effekte aus, um zu testen, ob der Gesang mit oder ohne den jeweiligen Effekt besser klingt. Der Bypass-Test ist der einfachste Weg, um herauszufinden, welche Effekte den größten Beitrag leisten.
Häufige Fehler bei der Reihenfolge der Gesangskette
Hier sind ein paar Dinge, die du beachten solltest, insbesondere als Anfänger:
Diese Kette ist keine verbindliche Checkliste. Nicht jede Gesangsaufnahme benötigt jeden einzelnen dieser Effekte. Wichtig ist, die allgemeine Reihenfolge im Auge zu behalten. Je nach Gesangsaufnahme, Musikgenre usw. können einige davon in deinem Mix überflüssig sein. Hör zuerst hin; füge nur hinzu, was fehlt.
Setze Reverb oder Delay nicht zu früh in der Kette ein. Zeitbasierte Effekte verteilen das Signal über die Zeit. Alle nachgeschalteten Prozesse, die das Signal verteilen – einschließlich Kompression, die dann auf den Reverb-Ausklang reagiert und den Gesang aufbläht.
Platzieren Sie den Kompressor früh in der Kette. Ein spät eingefügter Kompressor reagiert eher auf das bearbeitete Signal als auf den trockenen Gesang und kann zu übertriebenen Hall- oder Delay-Wiederholungen führen.
Verwende einen Cleanup-EQ vor dem Tone-Shaping-EQ. Der Tone-Shaping-EQ ist optional, sollte aber immer erst zum Einsatz kommen, nachdem du unerwünschte Frequenzen mit einem Cleanup-EQ aus deiner Aufnahme entfernt hast.
Wende Vocal-Effekte nicht nur im Solo-Modus an. Einstellungen, die auf einer isolierten Gesangsspur richtig klingen, können im Kontext oft falsch klingen. Schalte den Solo-Modus der Gesangsspur aus und höre dir den Kontext an, nachdem du jeden Effekt angepasst hast.
FAQ
Eine Vocal-Kette ist eine Abfolge von Audioeffekten, die nacheinander auf eine Gesangsspur angewendet werden. Das Signal durchläuft nacheinander jeden Effekt – typischerweise EQ, Kompression, De-Essing, Sättigung, Delay und Hall –, wobei jeder Effekt das Signal transformiert, bevor es an den nächsten weitergeleitet wird. Der Zweck der Kette besteht darin, einen rohen Gesang klar und musikalisch in einen fertigen Mix einzubetten.
Die Standardreihenfolge lautet: Cleanup-EQ → Kompression → De-Essing → Klangformungs-EQ → Sättigung → Delay → Hall → Limiter. Der subtraktive EQ kommt zuerst, um das Signal zu bereinigen, die dynamische Steuerung (Kompression) folgt früh, um die Lautstärke auszugleichen, die Klangformung (EQ, Sättigung) erfolgt, nachdem problematische Frequenzen entfernt und die Dynamik ausgeglichen wurde, und zeitbasierte Effekte (Hall, Delay) kommen zuletzt.
Der Cleanup-EQ kommt vor der Kompression, damit der Kompressor auf ein sauberes Signal reagiert, anstatt mit matschigen Frequenzen zu kämpfen. Der Tone-Shaping-EQ kommt nach der Kompression, um die Präsenz eines kontrollierten Signals zu verstärken. Aus diesem Grund verwenden die meisten professionellen Gesangsketten mehrere EQ-Instanzen an verschiedenen Positionen.
Ein spezieller De-Esser ist hilfreich, aber nicht zwingend erforderlich. Die gleiche Aufgabe – das Einbinden von scharfen Zischlauten im Bereich von 5–10 kHz – lässt sich mit einem schmalen EQ-Cut erledigen. Schleife den Teil der Aufnahme mit besonders ausgeprägten Zischlauten (scharf klingende „s“), füge einen Equalizer mit sehr schmalem Q hinzu und scanne den Bereich um 5–10 kHz. Finde die Stelle mit der stärksten Resonanz und senke sie um 3–6 dB ab.
Amped Studio bietet keine Echtzeit-Tonhöhenkorrektur in der Effektkette. Für eine vollständige Nachstimmung bearbeiten Sie die Tonhöhe vor der Kette mit einem Autotune-Plugin. Bei vereinzelten Fehlern – wie einer einzelnen zu tiefen Note in einer ansonsten soliden Aufnahme – schneiden Sie den Audioabschnitt um die problematische Silbe im Audio-Editor aus und verwenden Sie den Pitch-Editor, um die Tonhöhe dieses Segments nach oben oder unten zu verschieben.
Beginne in Minuten, Beats und Songs zu erstellen. Keine Erfahrung nötig — so einfach ist das.
Jetzt starten